8 Exploratory factor analysis
8.1 Introduction
In this chapter, we will focus on exploratory factor analysis.
Generally, factor analysis is a class of procedures used for data reduction or summary. It is an interdependence technique, meaning that there is no distinction between dependent and independent variables and all variables are considered simultaneously. In exploratory factor analysis, specific hypotheses about how many factors will emerge, and what items these factors will comprise are not requires (as opposed to confirmatory factor analysis). Principal Components Analysis (PCA) is one of the most frequently used techniques. The goals are …
- To identify underlying dimensions, or factors, that explain the correlations among a set of variables
- To identify a new, smaller set of uncorrelated variables to replace the original set of correlated variables in subsequent multivariate analysis (e.g., regression analysis, t-test, etc.)
To see what this means, let’s use a simple example. Say, you wanted to explain the motives underlying the purchasing of toothpaste. You come up with six items that represent different motives of purchasing toothpaste:
- Item 1: It is important to buy toothpaste that prevents cavities.
- Item 2: I like a toothpaste that gives shiny teeth.
- Item 3: A toothpaste should strengthen your gums.
- Item 4: I prefer a toothpaste that freshens breath.
- Item 5: Prevention of tooth decay should not be an important benefit offered by a toothpaste.
- Item 6: The most important consideration in buying a toothpaste is attractive teeth.
Let’s assume you collect data from 30 respondents and you use 7-point itemized rating scales to measure the extent of agreement to each of these statements. This is the data that you have collected:
factor_analysis <- read.table("https://raw.githubusercontent.com/IMSMWU/Teaching/master/MRDA2017/toothpaste.dat",
sep = "\t", header = TRUE) #read in data
str(factor_analysis) #inspect data## 'data.frame': 30 obs. of 6 variables:
## $ prevent_cavities: int 7 1 6 4 1 6 5 6 3 2 ...
## $ shiny_teeth : int 3 3 2 5 2 3 3 4 4 6 ...
## $ strengthen_gum : int 6 2 7 4 2 6 6 7 2 2 ...
## $ fresh_breath : int 4 4 4 6 3 4 3 4 3 6 ...
## $ prevent_decay : int 6 3 7 6 2 6 4 7 2 1 ...
## $ attract_teeth : int 4 4 3 5 2 4 3 4 3 6 ...head(factor_analysis) #inspect dataA construct is a specific type of concept that exists at a higher level of abstraction than everyday concepts. In this example, the perceived benefits of toothpaste represent the construct that we would like to measure. The construct is unobservable (‘latent’) but it can be inferred from other measurable variables (items) that together comprise a scale (latent construct). A multi-item scale consists of multiple items, where an item is a single question or statement to be evaluated. In the above example, we use six items to measure the perceived benefits of toothpaste. If several items correlate highly, they might measure aspects of a common underlying dimension (a.k.a. factors). That is, specific patterns in the correlation matrix signal the existence of one or more factors underlying the data. Let’s inspect the correlation matrix using the rcorr() function from the Hmisc package.
library("Hmisc")
rcorr(as.matrix(factor_analysis))## prevent_cavities shiny_teeth strengthen_gum fresh_breath
## prevent_cavities 1.00 -0.05 0.87 -0.09
## shiny_teeth -0.05 1.00 -0.16 0.57
## strengthen_gum 0.87 -0.16 1.00 -0.25
## fresh_breath -0.09 0.57 -0.25 1.00
## prevent_decay 0.86 -0.02 0.78 0.01
## attract_teeth 0.00 0.64 -0.02 0.64
## prevent_decay attract_teeth
## prevent_cavities 0.86 0.00
## shiny_teeth -0.02 0.64
## strengthen_gum 0.78 -0.02
## fresh_breath 0.01 0.64
## prevent_decay 1.00 0.14
## attract_teeth 0.14 1.00
##
## n= 30
##
##
## P
## prevent_cavities shiny_teeth strengthen_gum fresh_breath
## prevent_cavities 0.7800 0.0000 0.6508
## shiny_teeth 0.7800 0.4134 0.0010
## strengthen_gum 0.0000 0.4134 0.1868
## fresh_breath 0.6508 0.0010 0.1868
## prevent_decay 0.0000 0.9175 0.0000 0.9725
## attract_teeth 0.9826 0.0001 0.9245 0.0001
## prevent_decay attract_teeth
## prevent_cavities 0.0000 0.9826
## shiny_teeth 0.9175 0.0001
## strengthen_gum 0.0000 0.9245
## fresh_breath 0.9725 0.0001
## prevent_decay 0.4723
## attract_teeth 0.4723You can see that some of the items correlate highly, while others don’t. Specifically, there appear to be two groups of items that correlate highly and that might represent underlying dimensions of the construct:
- Factor 1: Items 1, 3, 5
- Factor 2: Items 2, 4, 6
Going back to the specific wording of the items you can see that the first group of items (i.e., items 1,3,5) refer to the health benefits, while the second item group (i.e., items 2,4,6) refer to the social benefits. Imagine now, for example, you would like to include the above variables as explanatory variables in a regression model. Due to the high degree of correlation among the items, you are likely to run into problems of multicollinearity. Instead of omitting some of the items, you might try to combine highly correlated items into one variable. Another application could be when you are developing a new measurement scale for a construct and you wish to explore the underlying dimensions of this construct. In these applications, you need to make sure that the questions that you are asking actually relate to the construct that you intend to measure.
The goal of factor analysis is to explain the maximum amount of total variance in a correlation matrix by transforming the original variables into linear components. This means that the correlation matrix is broken down into a smaller set of dimensions. The generalized formal representation of the linear relationship between a latent factor Y and the set of variables can be written as:
\[\begin{equation} Y_i=b_1X_{1i} + b_2X_{2i} + b_nX_{ni}+\epsilon_i \tag{8.1} \end{equation}\]
where Xn represents the data that we have collected for the different variables. To make it more explicit, the equation could also be written as
\[\begin{equation} Factor_i=b_1Variable_{1i} + b_2Variable_{2i} + b_nVariable_{ni}+\epsilon_i \tag{8.2} \end{equation}\]
where the dependent variable “Factor” refers to the factor score of person i on the underlying dimensions. In our case, the initial inspection suggested two underlying factors (i.e., health benefits and social benefits), so that we can construct two equations that describe both factors in terms of the variables that we have measured:
\[\begin{equation} Health_i=b_1X_{1i} + b_2X_{2i} + b_3X_{3i}+ b_4X_{4i}+ b_5X_{5i}+ b_6X_{6i}+\epsilon_i \tag{8.3} \end{equation}\]
\[\begin{equation} Social_i=b_1X_{1i} + b_2X_{2i} + b_3X_{3i}+ b_4X_{4i}+ b_5X_{5i}+ b_6X_{6i}+\epsilon_i \tag{8.4} \end{equation}\]
where the b’s in each equation represent the factor loadings. You can see that both equations include the same set of predictors. However, their values in each equation will be different, depending on the importance of each variable to the respective factor. Once the factor loadings have been computed (we will see how this is done below), we can summarize them in a component matrix, which is usually denoted as A:
\[\mathbf{A} = \left[\begin{array} {rrr} 0.93 & 0.25 \\ -0.30 & 0.80 \\ 0.94 & 0.13 \\ -0.34 & 0.79 \\ 0.87 & 0.35 \\ -0.18 & 0.87 \end{array}\right]\]
The linear relation between the factors and the factor loadings can also be shown in a graph, where each axis represents a factor and the variables are placed on the coordinates according to the strength of the relationship between the variable and each factor. The greater the loading of variables on a factor, the more that factor explains relationships between those variables. You can also think of the factor loadings as the correlations between a factor and a variable.
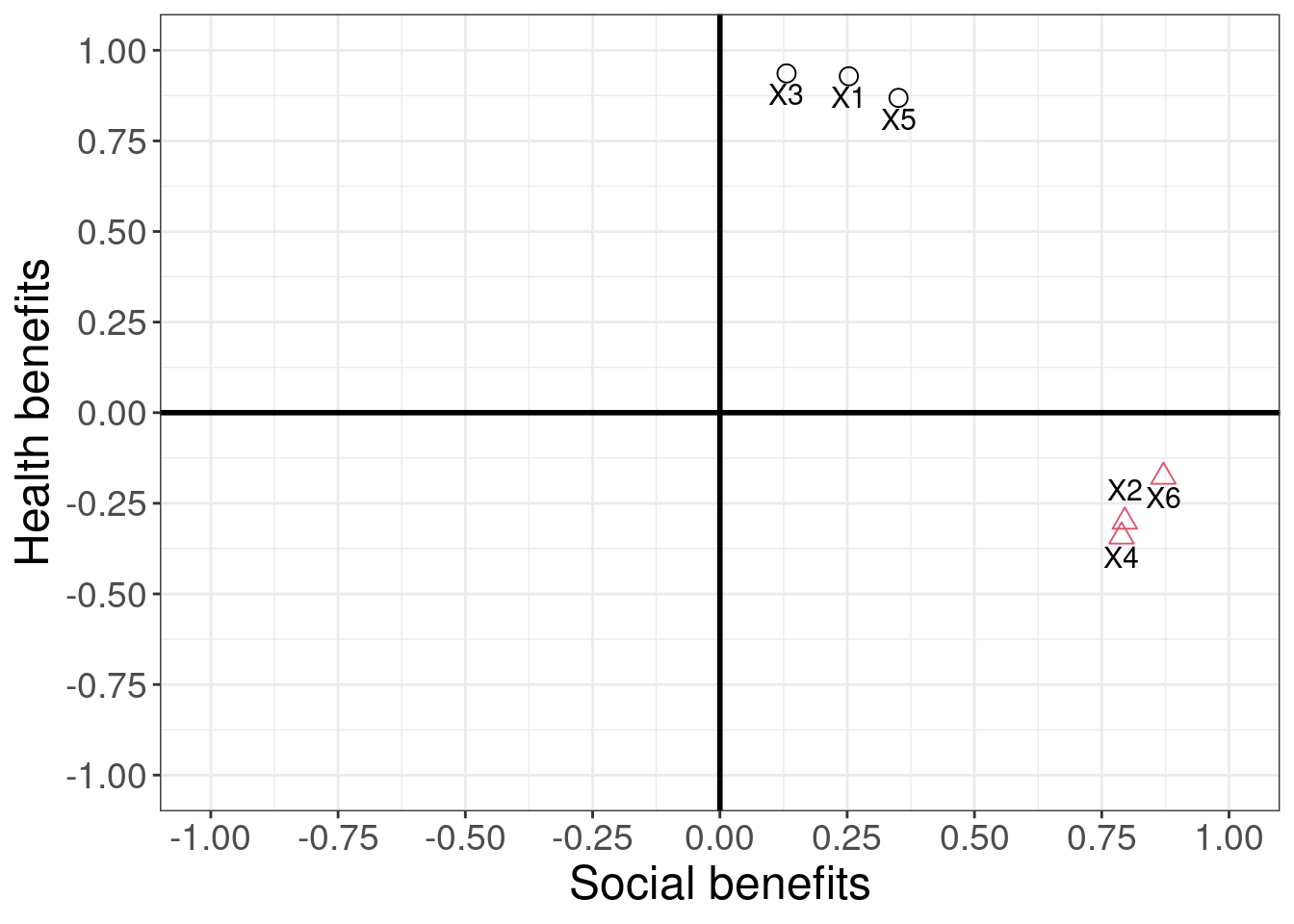
Figure 8.1: Factor loadings
The factor loadings may then be used to compute the two new variables (i.e., factor scores) representing the two underlying dimensions. Using a rather simplistic approach, the factor scores for person i could be computed by
\[\begin{equation} \begin{split} Health_i=& 0.93*preventCavities_{i} -0.3*shinyTeeth_{i} + 0.94*strengthenGum_{i}\\ &-0.34*freshBreath_{i} + 0.87*preventDecay_{i} - 0.18*attractTeeth_{i} \end{split} \tag{8.5} \end{equation}\]
\[\begin{equation} \begin{split} Social_i=& 0.25*preventCavities_{i} + 0.80*shinyTeeth_{i} + 0.13*strengthenGum_{i}\\ &+ 0.79*freshBreath_{i}+ 0.35*preventDecay_{i}+ 0.87*attractTeeth_{i} \end{split} \tag{8.6} \end{equation}\]
where the variable names are replaced by the values that were observed for respondent i to compute the factor scores for respondent i. This means that we have reduced the number of variables from six to two. Note that this is a rather simple approach that is intended to explain the underlying logic. However, that the resulting factor scores will depend on the measurement scales of the variables. If different measurement scales would be used, the resulting factor scores for different factors could not be compared. Thus, R will compute the factor scores using more sophisticated methods as we will see below.
8.2 Steps in factor analysis
Now that we have a broad understanding of how factor analysis works, let’s use another example to go through the process of deriving factors step by step. In this section, we will use the R anxiety questionnaire from the book by Andy Field et al.. The questionnaire is intended to measure the various aspects of student’s anxiety towards learning R. It includes 23 items for which respondents are asked to indicate on a five-point Likert scale to what extent they agree with the respective statements. The questionnaire is shown in the following figure:

The R anxiety questionnaire (source: Field, A. et al. (2012): Discovering Statistics Using R, p. 768)
Let’s assume, we have collected data from 2,571 respondents and stored the results in the data set “raq.dat.”
raq_data <- read.table("https://raw.githubusercontent.com/IMSMWU/Teaching/master/MRDA2017/raq.dat",
sep = "\t", header = TRUE) #read in data8.2.1 Are the assumptions satisfied?
Since PCA is based the correlation between variables, the first step is to inspect the correlation matrix, which can be created using the cor() function.
raq_matrix <- cor(raq_data)
round(raq_matrix, 3)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10
## Q01 1.000 -0.099 -0.337 0.436 0.402 0.217 0.305 0.331 -0.092 0.214
## Q02 -0.099 1.000 0.318 -0.112 -0.119 -0.074 -0.159 -0.050 0.315 -0.084
## Q03 -0.337 0.318 1.000 -0.380 -0.310 -0.227 -0.382 -0.259 0.300 -0.193
## Q04 0.436 -0.112 -0.380 1.000 0.401 0.278 0.409 0.349 -0.125 0.216
## Q05 0.402 -0.119 -0.310 0.401 1.000 0.257 0.339 0.269 -0.096 0.258
## Q06 0.217 -0.074 -0.227 0.278 0.257 1.000 0.514 0.223 -0.113 0.322
## Q07 0.305 -0.159 -0.382 0.409 0.339 0.514 1.000 0.297 -0.128 0.284
## Q08 0.331 -0.050 -0.259 0.349 0.269 0.223 0.297 1.000 0.016 0.159
## Q09 -0.092 0.315 0.300 -0.125 -0.096 -0.113 -0.128 0.016 1.000 -0.134
## Q10 0.214 -0.084 -0.193 0.216 0.258 0.322 0.284 0.159 -0.134 1.000
## Q11 0.357 -0.144 -0.351 0.369 0.298 0.328 0.345 0.629 -0.116 0.271
## Q12 0.345 -0.195 -0.410 0.442 0.347 0.313 0.423 0.252 -0.167 0.246
## Q13 0.355 -0.143 -0.318 0.344 0.302 0.466 0.442 0.314 -0.167 0.302
## Q14 0.338 -0.165 -0.371 0.351 0.315 0.402 0.441 0.281 -0.122 0.255
## Q15 0.246 -0.165 -0.312 0.334 0.261 0.360 0.391 0.300 -0.187 0.295
## Q16 0.499 -0.168 -0.419 0.416 0.395 0.244 0.389 0.321 -0.189 0.291
## Q17 0.371 -0.087 -0.327 0.383 0.310 0.282 0.391 0.590 -0.037 0.218
## Q18 0.347 -0.164 -0.375 0.382 0.322 0.513 0.501 0.280 -0.150 0.293
## Q19 -0.189 0.203 0.342 -0.186 -0.165 -0.167 -0.269 -0.159 0.249 -0.127
## Q20 0.214 -0.202 -0.325 0.243 0.200 0.101 0.221 0.175 -0.159 0.084
## Q21 0.329 -0.205 -0.417 0.410 0.335 0.272 0.483 0.296 -0.136 0.193
## Q22 -0.104 0.231 0.204 -0.098 -0.133 -0.165 -0.168 -0.079 0.257 -0.131
## Q23 -0.004 0.100 0.150 -0.034 -0.042 -0.069 -0.070 -0.050 0.171 -0.062
## Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20
## Q01 0.357 0.345 0.355 0.338 0.246 0.499 0.371 0.347 -0.189 0.214
## Q02 -0.144 -0.195 -0.143 -0.165 -0.165 -0.168 -0.087 -0.164 0.203 -0.202
## Q03 -0.351 -0.410 -0.318 -0.371 -0.312 -0.419 -0.327 -0.375 0.342 -0.325
## Q04 0.369 0.442 0.344 0.351 0.334 0.416 0.383 0.382 -0.186 0.243
## Q05 0.298 0.347 0.302 0.315 0.261 0.395 0.310 0.322 -0.165 0.200
## Q06 0.328 0.313 0.466 0.402 0.360 0.244 0.282 0.513 -0.167 0.101
## Q07 0.345 0.423 0.442 0.441 0.391 0.389 0.391 0.501 -0.269 0.221
## Q08 0.629 0.252 0.314 0.281 0.300 0.321 0.590 0.280 -0.159 0.175
## Q09 -0.116 -0.167 -0.167 -0.122 -0.187 -0.189 -0.037 -0.150 0.249 -0.159
## Q10 0.271 0.246 0.302 0.255 0.295 0.291 0.218 0.293 -0.127 0.084
## Q11 1.000 0.335 0.423 0.325 0.365 0.369 0.587 0.373 -0.200 0.255
## Q12 0.335 1.000 0.489 0.433 0.332 0.408 0.333 0.493 -0.267 0.298
## Q13 0.423 0.489 1.000 0.450 0.342 0.358 0.408 0.533 -0.227 0.204
## Q14 0.325 0.433 0.450 1.000 0.380 0.418 0.354 0.498 -0.254 0.226
## Q15 0.365 0.332 0.342 0.380 1.000 0.454 0.373 0.343 -0.210 0.206
## Q16 0.369 0.408 0.358 0.418 0.454 1.000 0.410 0.422 -0.267 0.265
## Q17 0.587 0.333 0.408 0.354 0.373 0.410 1.000 0.376 -0.163 0.205
## Q18 0.373 0.493 0.533 0.498 0.343 0.422 0.376 1.000 -0.257 0.235
## Q19 -0.200 -0.267 -0.227 -0.254 -0.210 -0.267 -0.163 -0.257 1.000 -0.249
## Q20 0.255 0.298 0.204 0.226 0.206 0.265 0.205 0.235 -0.249 1.000
## Q21 0.346 0.441 0.374 0.399 0.300 0.421 0.363 0.430 -0.275 0.468
## Q22 -0.162 -0.167 -0.195 -0.170 -0.168 -0.156 -0.126 -0.160 0.234 -0.100
## Q23 -0.086 -0.046 -0.053 -0.048 -0.062 -0.082 -0.092 -0.080 0.122 -0.035
## Q21 Q22 Q23
## Q01 0.329 -0.104 -0.004
## Q02 -0.205 0.231 0.100
## Q03 -0.417 0.204 0.150
## Q04 0.410 -0.098 -0.034
## Q05 0.335 -0.133 -0.042
## Q06 0.272 -0.165 -0.069
## Q07 0.483 -0.168 -0.070
## Q08 0.296 -0.079 -0.050
## Q09 -0.136 0.257 0.171
## Q10 0.193 -0.131 -0.062
## Q11 0.346 -0.162 -0.086
## Q12 0.441 -0.167 -0.046
## Q13 0.374 -0.195 -0.053
## Q14 0.399 -0.170 -0.048
## Q15 0.300 -0.168 -0.062
## Q16 0.421 -0.156 -0.082
## Q17 0.363 -0.126 -0.092
## Q18 0.430 -0.160 -0.080
## Q19 -0.275 0.234 0.122
## Q20 0.468 -0.100 -0.035
## Q21 1.000 -0.129 -0.068
## Q22 -0.129 1.000 0.230
## Q23 -0.068 0.230 1.000If the variables measure the same construct, we would expect to see a certain degree of correlation between the variables. Even if the variables turn out to measure different dimensions of the same underlying construct, we would still expect to see some degree of correlation. So the first problem that could occur is that the correlations are not high enough. A first approach would be to scan the correlation matrix for correlations lower than about 0.3 and identify variables that have many correlations below this threshold. If your data set contains many variables, this task can be quite tedious. To make the task a little easier, you could proceed as follows.
Create a dataframe from the correlation matrix and set the diagonal elements to missing since these are always 1:
correlations <- as.data.frame(raq_matrix)
diag(correlations) <- NANow we can use the apply() function to count the number of correlations for each variable that are below a certain threshold (say, 0.3). The apply() function is very useful as it lets you apply function by the rows or columns in your dataframe. In the following example abs(correlations) < 0.3 returns a logical value for the correlation matrix that returns TRUE if the statement is true. The second argument 1 means that the function should be applied to the rows (2 would apply it to the columns). The third argument states the function that should be applied. In our case, we would like to count the number of absolute correlations below 0.3 so we apply the sum function, which sums the number of TRUE occurrences by row. The final argument na.rm = TRUE simply tells R to neglect the missing values that we have created for the diagonals of the matrix.
apply(abs(correlations) < 0.3, 1, sum, na.rm = TRUE)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20
## 9 20 6 8 11 14 8 16 21 20 8 8 6 8 11 8 8 8 21 20
## Q21 Q22 Q23
## 9 22 22The output shows you the number of correlations below the threshold for each variable. In a similar way, it would also be possible to compute the mean correlation for each variable.
apply(abs(correlations), 1, mean, na.rm = TRUE)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08
## 0.2786461 0.1590732 0.3193955 0.3044131 0.2671130 0.2685230 0.3341477 0.2581210
## Q09 Q10 Q11 Q12 Q13 Q14 Q15 Q16
## 0.1555957 0.2105303 0.3197517 0.3263889 0.3277661 0.3179673 0.2902898 0.3345197
## Q17 Q18 Q19 Q20 Q21 Q22 Q23
## 0.3084564 0.3421177 0.2173012 0.2121990 0.3222743 0.1621558 0.0798525Another way to make the correlations more salient is to plot the correlation matrix using different colors that indicate the strength of the correlations. This can be done using the corPolot() function from the psych package.
corPlot(correlations, numbers = TRUE, upper = FALSE,
diag = FALSE, main = "Correlations between variables")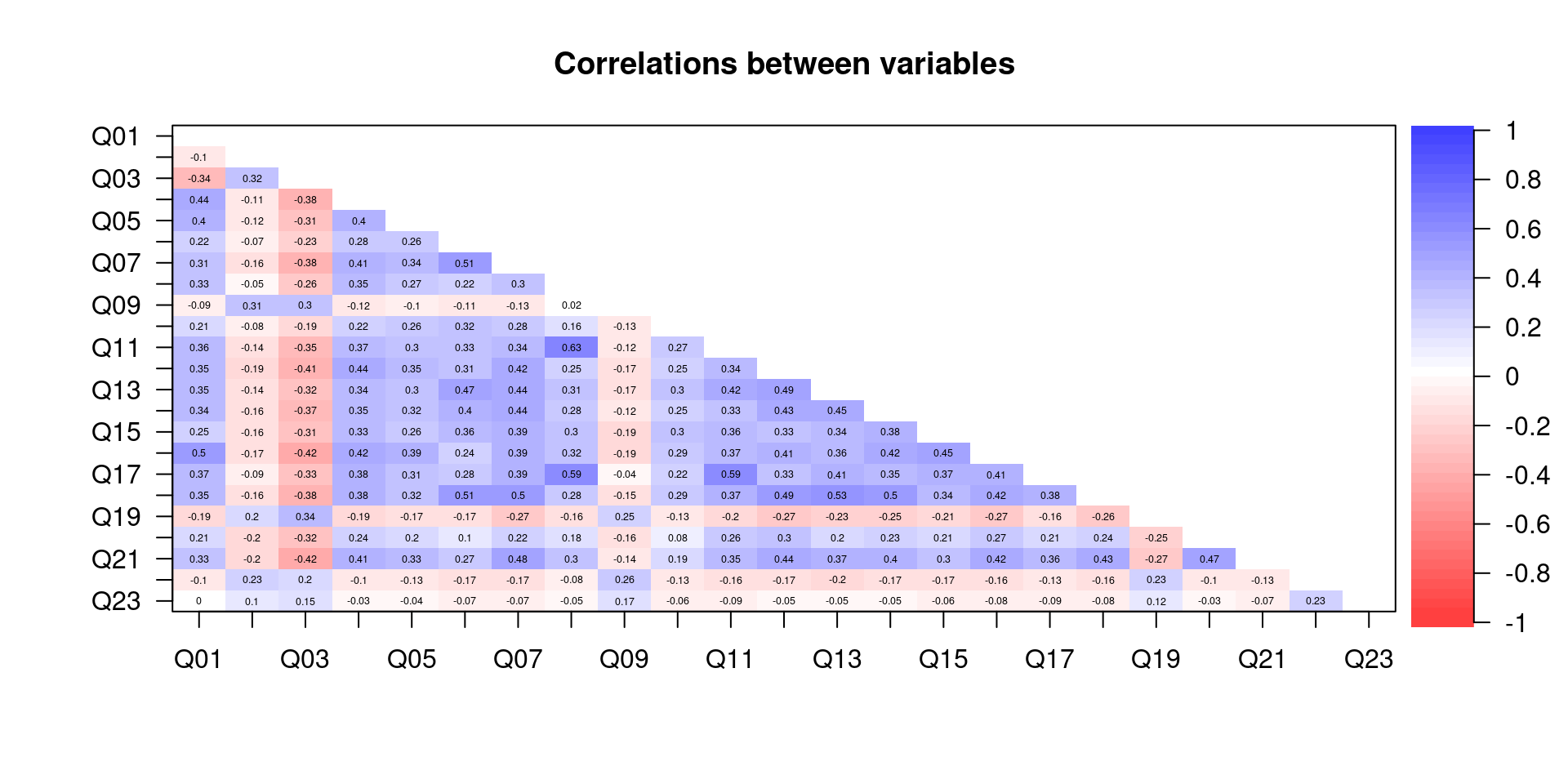
Figure 8.2: Correlation matrix
You will, however, notice that this is a rather subjective approach. The Bartlett’s test is a statistical test that can be used to test whether all the off-diagonal elements in the population correlation matrix are zero (i.e., whether the population correlation matrix resembles an identify matrix). Thus, it tests whether the correlations are overall too small. If the matrix is an identify matrix, it means that all variables are independent. Thus, a significant test statistic (i.e., p < 0.05) indicates that there is some relationship between variables. The test can be implemented using the cortest.bartlett() function from the psych package:
library(psych)
cortest.bartlett(raq_matrix, n = nrow(raq_data))## $chisq
## [1] 19334.49
##
## $p.value
## [1] 0
##
## $df
## [1] 253In our example, the p-value is less than 0.05, which is good news since it confirms that overall the correlation between variables is different from zero.
The other problem that might occur is that the correlations are too high. Actually, a certain degree of multicollinearity is not a problem in PCA. However, it is important to avoid extreme multicollinearity (i.e., variables are highly correlated) and singularity (i.e., variables are perfectly correlated). Multicollinearity causes problems, because it becomes difficult to determine the unique contribution of a variable (as was the case in linear regression analysis). Again, inspecting the entire correlation matrix when there are many variables will be a tedious task. .
apply(abs(correlations) > 0.8, 1, sum, na.rm = TRUE)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20
## 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## Q21 Q22 Q23
## 0 0 0The results do not suggest any extreme or perfect correlations. Again, there is a more objective measure that could be applied. The determinant tells us whether the correlation matrix is singular (determinant = 0), or if all variables are completely unrelated (determinant = 1), or somewhere in between. As a rule of thumb, the determinant should be greater than 0.00001. The det() function can be used to compute the determinant:
det(raq_matrix)## [1] 0.0005271037det(raq_matrix) > 0.00001## [1] TRUEAs you can see, the determinant is larger than the threshold, indicating that the overall correlation between variables is not too strong.
Finally, you should test if the correlation pattern in the matrix is appropriate for factor analysis using the Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy. This statistic is a measure of the proportion of variance among variables that might be common variance.
\[\begin{equation} MSA_j=\frac{\sum_{k\ne j}^{}{r^2_{jk}}}{\sum_{k\ne j}^{}{r^2_{jk}}+\sum_{k\ne j}^{}{p^2_{jk}}} \tag{8.7} \end{equation}\]
where \(r_{jk}\) is the correlation between two variables of interest and \(p_{jk}\) is their partial correlation. The partial correlation measures the degree of association between the two variables, when the effect of the remaining variables is controlled for. It can takes values between 0 (bad) and 1 (good), where a value of 0 indicates that the sum of partial correlations is large relative to the sum of correlations. If the remaining correlation between two variables remains high if you control for all the other variables, this provides an indication that the correlation is fairly concentrated and on a subset of the variables and factor analysis is likely to be inappropriate. In contrast, a value close to 1 means that the sum of the partial correlations is fairly is low, indicating a more compact pattern of correlations between a larger set of variables. Values should at least exceed 0.50, with the thresholds:
- <.50 = unacceptable
- >.50 = miserable
- >.60 = mediocre
- >.70 = middling
- >.80 = meritorious
- >.90 = marvelous
The KMO measure of sampling adequacy can be computed using the KMO() function from the psych package:
KMO(raq_data)## Kaiser-Meyer-Olkin factor adequacy
## Call: KMO(r = raq_data)
## Overall MSA = 0.93
## MSA for each item =
## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10 Q11 Q12 Q13 Q14 Q15 Q16
## 0.93 0.87 0.95 0.96 0.96 0.89 0.94 0.87 0.83 0.95 0.91 0.95 0.95 0.97 0.94 0.93
## Q17 Q18 Q19 Q20 Q21 Q22 Q23
## 0.93 0.95 0.94 0.89 0.93 0.88 0.77You can see that the statistic is calculated for the entire matrix and for each variable individually. In our example, the values for all variables as well as the overall matrix is above 0.5, suggesting that factor analysis is appropriate.
8.2.2 Deriving factors
After testing that the data can be used for PCA, we can move on to conducting PCA. Conducting PCA is fairly simple in R using the pricipal() function from the psych package. However, before the apply the function to our data, it is useful to reflect on the goals of PCA again. The goal is to explain the maximum amount of total variance in a correlation matrix by transforming the original variables into a smaller set of linear components (factors). So the first decision we have to make is how many factors we should extract. There are different methods that can be used to decide on the appropriate number of factors, including:
- A priori determination: Requires prior knowledge
- Determination based on percentage of variance: When cumulative percentage of variance extracted by the factors reaches a satisfactory level (e.g., factors extracted should account for at least 60% of the variance)
- Eigenvalues: Eigenvalues refer to the total variance that is explained by each factor. Factors with eigenvalues greater than 1.0 are retained (factors with a variance less than 1.0 are no better than a single variable)
- Scree plot: Is a plot of the eigenvalues against the number of factors in order of extraction. Assumption: the point at which the scree begins denotes the true number of factors.
Often, the decision is made based on a combination of different criteria.
By extracting as many factors as there are variables we can inspect their eigenvalues and make decisions about which factors to extract. Since we have 23 variables, we set the argument nfactors to 23.
pc1 <- principal(raq_data, nfactors = 23, rotate = "none")
pc1## Principal Components Analysis
## Call: principal(r = raq_data, nfactors = 23, rotate = "none")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11 PC12
## Q01 0.59 0.18 -0.22 0.12 -0.40 -0.11 -0.22 -0.08 0.01 -0.10 0.11 -0.12
## Q02 -0.30 0.55 0.15 0.01 -0.03 -0.38 0.19 -0.39 0.01 -0.12 0.30 0.27
## Q03 -0.63 0.29 0.21 -0.07 0.02 0.00 0.01 -0.05 0.20 0.10 0.15 0.03
## Q04 0.63 0.14 -0.15 0.15 -0.20 -0.12 -0.06 0.11 -0.11 -0.01 -0.03 0.34
## Q05 0.56 0.10 -0.07 0.14 -0.42 -0.17 -0.06 0.11 0.24 0.09 -0.30 0.16
## Q06 0.56 0.10 0.57 -0.05 0.17 0.01 0.00 0.05 0.00 0.00 -0.13 0.20
## Q07 0.69 0.04 0.25 0.10 0.17 -0.08 0.05 0.03 -0.08 0.13 -0.27 0.20
## Q08 0.55 0.40 -0.32 -0.42 0.15 0.10 -0.07 -0.04 0.01 -0.05 -0.09 0.03
## Q09 -0.28 0.63 -0.01 0.10 0.17 -0.27 -0.01 -0.03 0.16 0.32 -0.22 -0.37
## Q10 0.44 0.03 0.36 -0.10 -0.34 0.22 0.44 -0.03 0.37 -0.22 -0.11 -0.21
## Q11 0.65 0.25 -0.21 -0.40 0.13 0.18 -0.01 0.03 0.10 -0.14 0.00 0.03
## Q12 0.67 -0.05 0.05 0.25 0.04 -0.08 -0.14 0.08 0.01 -0.11 0.19 -0.07
## Q13 0.67 0.08 0.28 -0.01 0.13 0.03 -0.21 0.05 0.08 -0.22 0.24 -0.08
## Q14 0.66 0.02 0.20 0.14 0.08 -0.03 -0.10 -0.06 -0.14 0.16 0.08 -0.29
## Q15 0.59 0.01 0.12 -0.11 -0.07 0.29 0.32 -0.12 -0.27 0.41 0.15 0.09
## Q16 0.68 0.01 -0.14 0.08 -0.32 0.00 0.12 -0.14 -0.19 0.15 0.16 -0.19
## Q17 0.64 0.33 -0.21 -0.34 0.10 0.05 -0.02 0.03 -0.04 0.02 0.01 -0.03
## Q18 0.70 0.03 0.30 0.13 0.15 -0.09 -0.10 0.06 -0.06 -0.12 0.05 -0.11
## Q19 -0.43 0.39 0.10 -0.01 -0.15 0.07 0.05 0.68 0.02 0.16 0.29 0.04
## Q20 0.44 -0.21 -0.40 0.30 0.33 -0.01 0.34 0.03 0.33 0.02 0.21 0.04
## Q21 0.66 -0.06 -0.19 0.28 0.24 -0.15 0.18 0.10 0.12 0.08 -0.02 0.04
## Q22 -0.30 0.47 -0.12 0.38 0.07 0.12 0.31 0.12 -0.41 -0.39 -0.19 -0.10
## Q23 -0.14 0.37 -0.02 0.51 0.02 0.62 -0.28 -0.22 0.18 0.08 0.00 0.13
## PC13 PC14 PC15 PC16 PC17 PC18 PC19 PC20 PC21 PC22 PC23 h2
## Q01 0.30 -0.25 0.18 0.12 -0.05 -0.17 0.16 -0.01 -0.21 0.05 0.01 1
## Q02 -0.02 0.01 -0.24 -0.05 -0.08 0.00 0.01 -0.02 -0.02 0.03 0.02 1
## Q03 0.10 0.13 0.40 -0.06 0.43 0.08 0.09 0.05 0.01 0.00 0.05 1
## Q04 -0.32 -0.17 0.12 0.31 0.19 0.05 -0.21 0.04 0.09 -0.02 0.02 1
## Q05 0.12 0.48 -0.07 -0.08 -0.04 0.01 -0.04 0.00 -0.02 0.02 0.01 1
## Q06 0.24 -0.03 0.08 0.20 -0.14 0.05 0.09 -0.07 0.04 -0.32 -0.11 1
## Q07 0.04 -0.22 0.00 -0.23 0.03 -0.15 0.20 0.16 0.14 0.24 0.09 1
## Q08 -0.01 0.04 -0.04 0.03 0.10 0.07 0.12 -0.15 0.06 0.16 -0.36 1
## Q09 -0.17 -0.07 0.12 0.11 -0.19 -0.02 -0.08 -0.03 0.04 -0.01 0.03 1
## Q10 -0.17 -0.15 -0.07 0.03 0.07 -0.01 0.00 0.04 -0.03 0.02 -0.04 1
## Q11 0.02 0.03 -0.02 0.07 -0.05 0.07 0.07 -0.18 0.06 0.00 0.41 1
## Q12 -0.45 0.17 0.09 -0.10 -0.08 0.04 0.36 0.00 -0.04 -0.10 -0.02 1
## Q13 0.01 0.12 0.14 -0.11 -0.06 -0.32 -0.30 -0.06 0.16 0.08 -0.05 1
## Q14 0.07 0.14 -0.37 0.25 0.34 -0.09 0.06 0.02 0.03 -0.01 0.05 1
## Q15 -0.09 0.16 0.16 0.06 -0.12 -0.10 -0.04 -0.07 -0.19 0.10 0.00 1
## Q16 0.12 -0.08 0.06 -0.22 -0.03 0.22 -0.02 -0.04 0.35 -0.12 -0.01 1
## Q17 -0.01 -0.01 -0.05 -0.18 0.04 -0.04 -0.10 0.42 -0.15 -0.23 -0.01 1
## Q18 0.09 0.00 0.03 -0.01 -0.06 0.45 -0.15 0.08 -0.18 0.23 0.01 1
## Q19 0.06 -0.09 -0.16 -0.03 -0.06 0.01 0.05 -0.02 0.02 0.04 -0.02 1
## Q20 0.17 0.07 0.05 0.22 -0.09 0.00 0.04 0.18 0.10 0.06 -0.04 1
## Q21 0.03 -0.15 -0.04 -0.27 0.20 -0.03 -0.11 -0.31 -0.20 -0.13 -0.01 1
## Q22 0.08 0.15 0.09 0.01 0.04 -0.06 0.02 0.00 0.01 -0.01 0.01 1
## Q23 -0.01 -0.07 -0.12 -0.06 -0.03 0.05 -0.03 0.01 -0.01 -0.02 0.00 1
## u2 com
## Q01 0.00000000000000033 6.0
## Q02 -0.00000000000000067 6.1
## Q03 0.00000000000000089 4.4
## Q04 0.00000000000000000 4.9
## Q05 -0.00000000000000111 5.2
## Q06 0.00000000000000078 4.4
## Q07 0.00000000000000044 4.1
## Q08 -0.00000000000000067 5.7
## Q09 -0.00000000000000044 5.0
## Q10 0.00000000000000011 7.7
## Q11 0.00000000000000000 4.1
## Q12 0.00000000000000000 3.8
## Q13 0.00000000000000000 4.2
## Q14 -0.00000000000000044 4.3
## Q15 -0.00000000000000022 5.6
## Q16 -0.00000000000000111 4.0
## Q17 -0.00000000000000044 4.3
## Q18 0.00000000000000000 3.4
## Q19 0.00000000000000033 3.5
## Q20 0.00000000000000022 8.7
## Q21 0.00000000000000000 4.6
## Q22 -0.00000000000000022 7.2
## Q23 0.00000000000000089 4.2
##
## PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11
## SS loadings 7.29 1.74 1.32 1.23 0.99 0.90 0.81 0.78 0.75 0.72 0.68
## Proportion Var 0.32 0.08 0.06 0.05 0.04 0.04 0.04 0.03 0.03 0.03 0.03
## Cumulative Var 0.32 0.39 0.45 0.50 0.55 0.59 0.62 0.65 0.69 0.72 0.75
## Proportion Explained 0.32 0.08 0.06 0.05 0.04 0.04 0.04 0.03 0.03 0.03 0.03
## Cumulative Proportion 0.32 0.39 0.45 0.50 0.55 0.59 0.62 0.65 0.69 0.72 0.75
## PC12 PC13 PC14 PC15 PC16 PC17 PC18 PC19 PC20 PC21 PC22
## SS loadings 0.67 0.61 0.58 0.55 0.52 0.51 0.46 0.42 0.41 0.38 0.36
## Proportion Var 0.03 0.03 0.03 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02
## Cumulative Var 0.78 0.80 0.83 0.85 0.88 0.90 0.92 0.94 0.95 0.97 0.99
## Proportion Explained 0.03 0.03 0.03 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02
## Cumulative Proportion 0.78 0.80 0.83 0.85 0.88 0.90 0.92 0.94 0.95 0.97 0.99
## PC23
## SS loadings 0.33
## Proportion Var 0.01
## Cumulative Var 1.00
## Proportion Explained 0.01
## Cumulative Proportion 1.00
##
## Mean item complexity = 5
## Test of the hypothesis that 23 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0
## with the empirical chi square 0 with prob < NA
##
## Fit based upon off diagonal values = 1The output is quite complex, but we will focus only on the SS loadings for now, which are the Eigenvalues (a.k.a. sum of squared loadings). One common rule is to retain factors with eigenvalues greater than 1.0. So based on this rule, we would extract four factors (i.e., the SS loadings for the fifth factor is < 1).
You can also plot the eigenvalues against the number of factors in order of extraction using a so-called Scree plot:
plot(pc1$values, type = "b")
abline(h = 1, lty = 2)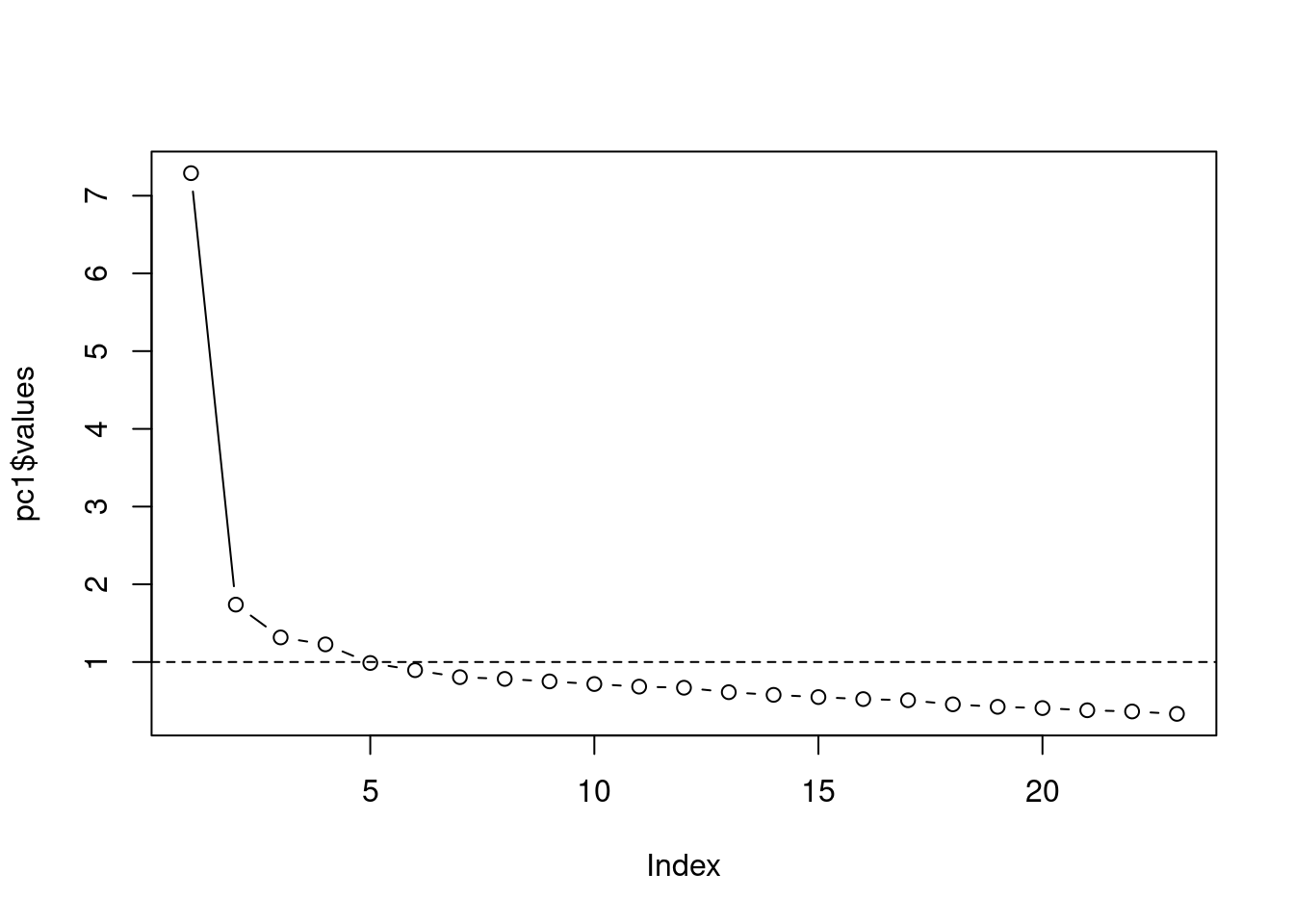
Figure 8.3: Scree plot
The dashed line is simply a visualization of the rule that we will retain factors with Eigenvalues > 1 (suggesting four factors). Another criterion based on this plot would be to find the point where the curve flattens (point of inflection). If the largest few eigenvalues in the covariance matrix dominate in magnitude, then the scree plot will exhibit an “elbow.” From that point onwards, the incremental gain in explained variance is rather low. Also according to this criterion, we would extract four factors. Taken together, the results suggest that we should extract four factors.
Now that we know how many components we want to extract, we can rerun the analysis, specifying that number:
pc2 <- principal(raq_data, nfactors = 4, rotate = "none")
pc2## Principal Components Analysis
## Call: principal(r = raq_data, nfactors = 4, rotate = "none")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PC1 PC2 PC3 PC4 h2 u2 com
## Q01 0.59 0.18 -0.22 0.12 0.43 0.57 1.6
## Q02 -0.30 0.55 0.15 0.01 0.41 0.59 1.7
## Q03 -0.63 0.29 0.21 -0.07 0.53 0.47 1.7
## Q04 0.63 0.14 -0.15 0.15 0.47 0.53 1.3
## Q05 0.56 0.10 -0.07 0.14 0.34 0.66 1.2
## Q06 0.56 0.10 0.57 -0.05 0.65 0.35 2.1
## Q07 0.69 0.04 0.25 0.10 0.55 0.45 1.3
## Q08 0.55 0.40 -0.32 -0.42 0.74 0.26 3.5
## Q09 -0.28 0.63 -0.01 0.10 0.48 0.52 1.5
## Q10 0.44 0.03 0.36 -0.10 0.33 0.67 2.1
## Q11 0.65 0.25 -0.21 -0.40 0.69 0.31 2.2
## Q12 0.67 -0.05 0.05 0.25 0.51 0.49 1.3
## Q13 0.67 0.08 0.28 -0.01 0.54 0.46 1.4
## Q14 0.66 0.02 0.20 0.14 0.49 0.51 1.3
## Q15 0.59 0.01 0.12 -0.11 0.38 0.62 1.2
## Q16 0.68 0.01 -0.14 0.08 0.49 0.51 1.1
## Q17 0.64 0.33 -0.21 -0.34 0.68 0.32 2.4
## Q18 0.70 0.03 0.30 0.13 0.60 0.40 1.4
## Q19 -0.43 0.39 0.10 -0.01 0.34 0.66 2.1
## Q20 0.44 -0.21 -0.40 0.30 0.48 0.52 3.2
## Q21 0.66 -0.06 -0.19 0.28 0.55 0.45 1.6
## Q22 -0.30 0.47 -0.12 0.38 0.46 0.54 2.8
## Q23 -0.14 0.37 -0.02 0.51 0.41 0.59 2.0
##
## PC1 PC2 PC3 PC4
## SS loadings 7.29 1.74 1.32 1.23
## Proportion Var 0.32 0.08 0.06 0.05
## Cumulative Var 0.32 0.39 0.45 0.50
## Proportion Explained 0.63 0.15 0.11 0.11
## Cumulative Proportion 0.63 0.78 0.89 1.00
##
## Mean item complexity = 1.8
## Test of the hypothesis that 4 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.06
## with the empirical chi square 4006.15 with prob < 0
##
## Fit based upon off diagonal values = 0.96Now that the output is less complex, we can inspect the remaining statistics. The first part of the output is the factor matrix, which contains the factor loadings of all the variables on the four extracted factors (i.e., PC1, PC2, PC3, PC4). As we have said before, the factor loadings are the correlations between the variables and the factors. The factor matrix also contains the columns “h2” and “u2.” “h2” refers to the communality, which is the proportion of variance a variable shares with all the other variables being considered. This is also the proportion of variance explained by the common factors. In contrast, “u2” refers to the unique variance, which is the proportion of the variance that is unique to a particular variable. In PCA, we are primarily interested in the common variance. When the communality is very low (say <.30), a variable is “quite unique” and should be removed, as it is definitely measuring “something else.” In our example, all communalities (i.e., h2) are above 0.3 so that we retain all variables.
Note that there is a difference between PCA and common factor analysis. PCA focuses on the variance and aims to reproduce the total variable variance. This means that the components reflect both common and unique variance of the variables. Factor analysis, in contrast, focuses on the correlation and aims to reproduce the correlations among variables. Here, the factors only represent the common variance that variable share and do not include the unique variance. In other words, while factor analysis focuses on explaining the off-diagonal terms in the correlation matrix (i.e., shared co-variance), PCA focuses on explaining the diagonal terms (i.e., the variances). However, although PCA aims to reproduce the on-diagonal terms in the correlation matrix, it also tends to fit the off-diagonal correlations quite well. Hence, the results are often comparable. See also here.
You should also take a closer look at the residuals in order to check whether you have extracted the correct number of factors. The difference between the reproduced and the actual correlation matrices are the residuals. We can extract the residuals from our model using the factor.residuals() function from the psych package. It takes the original correlation matrix and the factor loadings as arguments:
residuals <- factor.residuals(raq_matrix, pc2$loadings)
round(residuals, 3)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10
## Q01 0.565 0.013 0.035 -0.011 0.027 -0.001 -0.061 -0.081 -0.050 0.042
## Q02 0.013 0.586 -0.062 0.022 0.003 -0.041 -0.011 -0.052 -0.115 -0.023
## Q03 0.035 -0.062 0.470 0.019 0.035 -0.027 -0.009 0.011 -0.052 -0.013
## Q04 -0.011 0.022 0.019 0.531 0.002 0.000 -0.010 -0.041 -0.051 0.003
## Q05 0.027 0.003 0.035 0.002 0.657 -0.016 -0.041 -0.044 -0.016 0.053
## Q06 -0.001 -0.041 -0.027 0.000 -0.016 0.346 -0.014 0.040 -0.005 -0.139
## Q07 -0.061 -0.011 -0.009 -0.010 -0.041 -0.014 0.455 0.030 0.033 -0.098
## Q08 -0.081 -0.052 0.011 -0.041 -0.044 0.040 0.030 0.261 -0.039 -0.021
## Q09 -0.050 -0.115 -0.052 -0.051 -0.016 -0.005 0.033 -0.039 0.516 -0.018
## Q10 0.042 -0.023 -0.013 0.003 0.053 -0.139 -0.098 -0.021 -0.018 0.665
## Q11 -0.066 -0.046 0.006 -0.051 -0.050 0.038 -0.018 -0.061 -0.045 0.012
## Q12 -0.057 0.024 0.030 -0.006 -0.050 -0.076 -0.072 0.024 0.027 -0.038
## Q13 0.008 -0.021 0.024 -0.051 -0.058 -0.078 -0.091 0.001 -0.021 -0.096
## Q14 -0.024 -0.009 0.002 -0.060 -0.055 -0.075 -0.074 0.032 0.038 -0.091
## Q15 -0.065 -0.007 0.025 -0.009 -0.045 -0.047 -0.033 -0.039 -0.012 -0.018
## Q16 0.059 0.050 0.039 -0.050 -0.005 -0.056 -0.051 -0.068 -0.014 0.052
## Q17 -0.069 -0.039 0.003 -0.052 -0.049 -0.008 0.025 -0.105 -0.027 -0.033
## Q18 -0.020 -0.015 0.001 -0.042 -0.066 -0.048 -0.069 0.030 0.018 -0.110
## Q19 0.015 -0.153 -0.061 0.045 0.041 -0.020 -0.015 -0.056 -0.114 0.010
## Q20 -0.128 0.099 0.115 -0.110 -0.092 0.122 0.002 0.011 0.060 0.078
## Q21 -0.120 0.049 0.071 -0.070 -0.078 0.029 0.053 0.014 0.055 0.005
## Q22 -0.079 -0.102 -0.071 -0.049 -0.072 0.043 0.010 0.020 -0.161 0.066
## Q23 -0.049 -0.147 -0.008 -0.076 -0.070 0.013 -0.033 0.086 -0.152 0.048
## Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20
## Q01 -0.066 -0.057 0.008 -0.024 -0.065 0.059 -0.069 -0.020 0.015 -0.128
## Q02 -0.046 0.024 -0.021 -0.009 -0.007 0.050 -0.039 -0.015 -0.153 0.099
## Q03 0.006 0.030 0.024 0.002 0.025 0.039 0.003 0.001 -0.061 0.115
## Q04 -0.051 -0.006 -0.051 -0.060 -0.009 -0.050 -0.052 -0.042 0.045 -0.110
## Q05 -0.050 -0.050 -0.058 -0.055 -0.045 -0.005 -0.049 -0.066 0.041 -0.092
## Q06 0.038 -0.076 -0.078 -0.075 -0.047 -0.056 -0.008 -0.048 -0.020 0.122
## Q07 -0.018 -0.072 -0.091 -0.074 -0.033 -0.051 0.025 -0.069 -0.015 0.002
## Q08 -0.061 0.024 0.001 0.032 -0.039 -0.068 -0.105 0.030 -0.056 0.011
## Q09 -0.045 0.027 -0.021 0.038 -0.012 -0.014 -0.027 0.018 -0.114 0.060
## Q10 0.012 -0.038 -0.096 -0.091 -0.018 0.052 -0.033 -0.110 0.010 0.078
## Q11 0.310 0.020 0.020 -0.013 -0.045 -0.075 -0.094 0.020 -0.002 0.056
## Q12 0.020 0.487 0.030 -0.048 -0.042 -0.058 0.014 -0.020 0.036 -0.056
## Q13 0.020 0.030 0.464 -0.047 -0.091 -0.061 0.006 -0.023 0.004 0.041
## Q14 -0.013 -0.048 -0.047 0.512 -0.017 -0.011 0.012 -0.038 0.000 -0.015
## Q15 -0.045 -0.042 -0.091 -0.017 0.622 0.077 -0.025 -0.094 0.027 0.031
## Q16 -0.075 -0.058 -0.061 -0.011 0.077 0.513 -0.034 -0.024 0.032 -0.108
## Q17 -0.094 0.014 0.006 0.012 -0.025 -0.034 0.317 0.019 -0.001 0.009
## Q18 0.020 -0.020 -0.023 -0.038 -0.094 -0.024 0.019 0.403 0.003 0.020
## Q19 -0.002 0.036 0.004 0.000 0.027 0.032 -0.001 0.003 0.657 0.060
## Q20 0.056 -0.056 0.041 -0.015 0.031 -0.108 0.009 0.020 0.060 0.516
## Q21 0.005 -0.062 -0.010 -0.032 -0.036 -0.074 0.016 -0.009 0.049 0.010
## Q22 0.047 -0.031 0.007 -0.011 0.062 -0.004 0.019 0.023 -0.060 -0.032
## Q23 0.116 -0.057 0.026 -0.027 0.079 -0.032 0.049 -0.049 -0.073 -0.056
## Q21 Q22 Q23
## Q01 -0.120 -0.079 -0.049
## Q02 0.049 -0.102 -0.147
## Q03 0.071 -0.071 -0.008
## Q04 -0.070 -0.049 -0.076
## Q05 -0.078 -0.072 -0.070
## Q06 0.029 0.043 0.013
## Q07 0.053 0.010 -0.033
## Q08 0.014 0.020 0.086
## Q09 0.055 -0.161 -0.152
## Q10 0.005 0.066 0.048
## Q11 0.005 0.047 0.116
## Q12 -0.062 -0.031 -0.057
## Q13 -0.010 0.007 0.026
## Q14 -0.032 -0.011 -0.027
## Q15 -0.036 0.062 0.079
## Q16 -0.074 -0.004 -0.032
## Q17 0.016 0.019 0.049
## Q18 -0.009 0.023 -0.049
## Q19 0.049 -0.060 -0.073
## Q20 0.010 -0.032 -0.056
## Q21 0.450 -0.033 -0.100
## Q22 -0.033 0.536 -0.177
## Q23 -0.100 -0.177 0.588Note that the diagonal elements in the residual matrix correspond to the unique variance in each variable that cannot be explained by the factors (i.e., “u2” in the output above). For example, the proportion of unique variance for question 1 is 0.57, which is reflected in the first cell in the residual matrix. The off-diagonal elements represent the difference between the actual correlations and the correlation based on the reproduced correlation matrix for all variable pairs. To see this, the reproduced correlation matrix could be generated by using the factor.model() function:
reproduced_matrix <- factor.model(pc2$loadings)
round(reproduced_matrix, 3)## Q01 Q02 Q03 Q04 Q05 Q06 Q07 Q08 Q09 Q10
## Q01 0.435 -0.112 -0.372 0.447 0.376 0.218 0.366 0.412 -0.042 0.172
## Q02 -0.112 0.414 0.380 -0.134 -0.122 -0.033 -0.148 0.002 0.430 -0.061
## Q03 -0.372 0.380 0.530 -0.399 -0.345 -0.200 -0.373 -0.270 0.352 -0.181
## Q04 0.447 -0.134 -0.399 0.469 0.399 0.278 0.419 0.390 -0.073 0.212
## Q05 0.376 -0.122 -0.345 0.399 0.343 0.273 0.380 0.312 -0.080 0.205
## Q06 0.218 -0.033 -0.200 0.278 0.273 0.654 0.528 0.183 -0.108 0.461
## Q07 0.366 -0.148 -0.373 0.419 0.380 0.528 0.545 0.267 -0.161 0.382
## Q08 0.412 0.002 -0.270 0.390 0.312 0.183 0.267 0.739 0.055 0.180
## Q09 -0.042 0.430 0.352 -0.073 -0.080 -0.108 -0.161 0.055 0.484 -0.116
## Q10 0.172 -0.061 -0.181 0.212 0.205 0.461 0.382 0.180 -0.116 0.335
## Q11 0.423 -0.097 -0.357 0.419 0.348 0.290 0.363 0.691 -0.071 0.259
## Q12 0.402 -0.219 -0.440 0.448 0.397 0.388 0.495 0.228 -0.195 0.283
## Q13 0.347 -0.122 -0.342 0.395 0.360 0.545 0.533 0.313 -0.147 0.398
## Q14 0.362 -0.155 -0.373 0.411 0.370 0.477 0.514 0.249 -0.159 0.345
## Q15 0.311 -0.158 -0.337 0.343 0.306 0.406 0.425 0.339 -0.174 0.314
## Q16 0.440 -0.217 -0.458 0.466 0.400 0.300 0.439 0.390 -0.175 0.239
## Q17 0.439 -0.048 -0.331 0.434 0.359 0.290 0.365 0.695 -0.009 0.252
## Q18 0.368 -0.149 -0.376 0.424 0.388 0.562 0.570 0.250 -0.168 0.403
## Q19 -0.204 0.357 0.403 -0.231 -0.207 -0.147 -0.254 -0.104 0.363 -0.137
## Q20 0.342 -0.301 -0.440 0.353 0.292 -0.021 0.219 0.164 -0.218 0.006
## Q21 0.449 -0.254 -0.488 0.480 0.412 0.244 0.430 0.282 -0.191 0.188
## Q22 -0.025 0.333 0.275 -0.050 -0.060 -0.209 -0.179 -0.099 0.417 -0.197
## Q23 0.045 0.246 0.158 0.042 0.028 -0.082 -0.037 -0.136 0.323 -0.110
## Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20
## Q01 0.423 0.402 0.347 0.362 0.311 0.440 0.439 0.368 -0.204 0.342
## Q02 -0.097 -0.219 -0.122 -0.155 -0.158 -0.217 -0.048 -0.149 0.357 -0.301
## Q03 -0.357 -0.440 -0.342 -0.373 -0.337 -0.458 -0.331 -0.376 0.403 -0.440
## Q04 0.419 0.448 0.395 0.411 0.343 0.466 0.434 0.424 -0.231 0.353
## Q05 0.348 0.397 0.360 0.370 0.306 0.400 0.359 0.388 -0.207 0.292
## Q06 0.290 0.388 0.545 0.477 0.406 0.300 0.290 0.562 -0.147 -0.021
## Q07 0.363 0.495 0.533 0.514 0.425 0.439 0.365 0.570 -0.254 0.219
## Q08 0.691 0.228 0.313 0.249 0.339 0.390 0.695 0.250 -0.104 0.164
## Q09 -0.071 -0.195 -0.147 -0.159 -0.174 -0.175 -0.009 -0.168 0.363 -0.218
## Q10 0.259 0.283 0.398 0.345 0.314 0.239 0.252 0.403 -0.137 0.006
## Q11 0.690 0.315 0.403 0.338 0.410 0.444 0.681 0.353 -0.198 0.200
## Q12 0.315 0.513 0.459 0.481 0.374 0.466 0.319 0.513 -0.302 0.354
## Q13 0.403 0.459 0.536 0.497 0.433 0.419 0.402 0.556 -0.231 0.163
## Q14 0.338 0.481 0.497 0.488 0.397 0.429 0.342 0.537 -0.254 0.241
## Q15 0.410 0.374 0.433 0.397 0.378 0.378 0.399 0.437 -0.236 0.175
## Q16 0.444 0.466 0.419 0.429 0.378 0.487 0.443 0.446 -0.299 0.373
## Q17 0.681 0.319 0.402 0.342 0.399 0.443 0.683 0.357 -0.162 0.196
## Q18 0.353 0.513 0.556 0.537 0.437 0.446 0.357 0.597 -0.259 0.215
## Q19 -0.198 -0.302 -0.231 -0.254 -0.236 -0.299 -0.162 -0.259 0.343 -0.308
## Q20 0.200 0.354 0.163 0.241 0.175 0.373 0.196 0.215 -0.308 0.484
## Q21 0.342 0.503 0.384 0.431 0.336 0.494 0.347 0.439 -0.324 0.457
## Q22 -0.209 -0.136 -0.203 -0.159 -0.230 -0.152 -0.145 -0.183 0.294 -0.068
## Q23 -0.202 0.011 -0.079 -0.022 -0.141 -0.049 -0.140 -0.032 0.196 0.021
## Q21 Q22 Q23
## Q01 0.449 -0.025 0.045
## Q02 -0.254 0.333 0.246
## Q03 -0.488 0.275 0.158
## Q04 0.480 -0.050 0.042
## Q05 0.412 -0.060 0.028
## Q06 0.244 -0.209 -0.082
## Q07 0.430 -0.179 -0.037
## Q08 0.282 -0.099 -0.136
## Q09 -0.191 0.417 0.323
## Q10 0.188 -0.197 -0.110
## Q11 0.342 -0.209 -0.202
## Q12 0.503 -0.136 0.011
## Q13 0.384 -0.203 -0.079
## Q14 0.431 -0.159 -0.022
## Q15 0.336 -0.230 -0.141
## Q16 0.494 -0.152 -0.049
## Q17 0.347 -0.145 -0.140
## Q18 0.439 -0.183 -0.032
## Q19 -0.324 0.294 0.196
## Q20 0.457 -0.068 0.021
## Q21 0.550 -0.096 0.032
## Q22 -0.096 0.464 0.408
## Q23 0.032 0.408 0.412You can see that the reproduced correlation between the first and second variable is -0.112. From the correlation table from the beginning we know, however, that the observed correlation was -0.099. Hence, the difference between the observed and reproduced correlation is: (-0.099)-(-0.112) = 0.013, which corresponds to the residual of this variable pair in the residual matrix. Note that the diagonal elements in the reproduced matrix correspond to the communalities in the model summary above (i.e., “h2”).
A measure of fit can now be computed based on the size of the residuals. In the worst case, the residuals would be as large as the correlations in the original matrix, which would be the case if we extracted no factors at all. A measure of fit could therefore be the sum of the squared residuals divided by the sum of the squared correlations. We square the residuals to account for positive and negative deviations. Values >0.90 are considered indicators of good fit. From the output above, you can see that: “Fit based upon off diagonal values = 0.96.” Thus, we conclude that the model fit is sufficient.
You could also manually compute this statistic by summing over the squared residuals and correlations, take their ratio and subtract it from one (note that we use the upper.tri() function to use the upper triangle of the matrix only; this has the effect of discarding the diagonal elements and the elements below the diagonal).
ssr <- (sum(residuals[upper.tri((residuals))]^2)) #sum of squared residuals
ssc <- (sum(raq_matrix[upper.tri((raq_matrix))]^2)) #sum of squared correlations
1 - (ssr/ssc) #model fit## [1] 0.9645252In a next step, we check the size of the residuals. If fewer residuals than 50% have absolute values greater than 0.05 the model is a good fit. This can be tested using the following code. We first convert the residuals to a matrix and select the upper triangular again to avoid duplicates. Finally, we count all occurrences where the absolute value is larger than 0.05 and divide it by the number of total observations to get the proportion.
residuals <- as.matrix(residuals[upper.tri((residuals))])
large_res <- abs(residuals) > 0.05
sum(large_res)## [1] 91sum(large_res)/nrow(residuals)## [1] 0.3596838In our example, we can confirm that the proportion of residuals > 0.05 is less than 50%.
Another way to evaluate the residuals is by looking at their mean value (rather, we square the residuals first to account for positive and negative values, compute the mean and then take the square root).
sqrt(mean(residuals^2))## [1] 0.05549286This means that our mean residual is 0.055 and this value should be as low as possible.
Finally, we need to validate if the residuals are approximately normally distributed, which we do by using a histogram, a Q-Q plot and the Shapiro test.
hist(residuals)
Figure 8.4: Hinstogram of residuals
qqnorm(residuals)
qqline(residuals)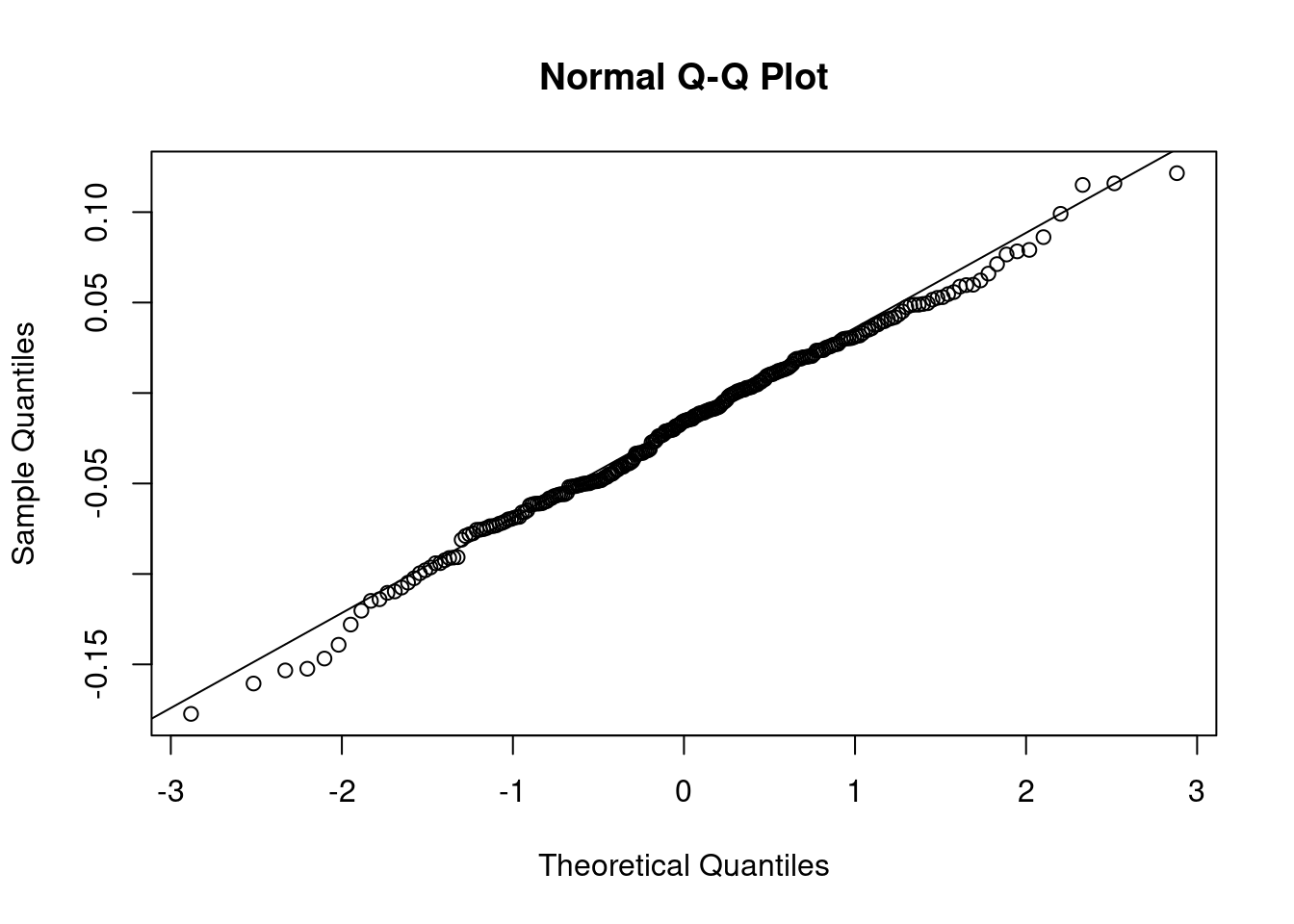
Figure 8.5: Q-Q plot
shapiro.test(residuals)##
## Shapiro-Wilk normality test
##
## data: residuals
## W = 0.99436, p-value = 0.4691All of the tests suggest that the distribution of the residuals is approximately normal.
8.2.3 Factor interpretation
To aid interpretation, it is possible to maximize the loading of a variable on one factor while minimizing its loading on all other factors. This is known as factor rotation. There are two types of factor rotation:
- orthogonal (assumes that factors are uncorrelated)
- oblique (assumes that factors are intercorrelated)
To carry out a orthogonal rotation, we change the rotate option in the principal() function from “none” to “varimax” (we could also exclude it altogether because varimax is the default if the option is not specified):
pc3 <- principal(raq_data, nfactors = 4, rotate = "varimax")
pc3## Principal Components Analysis
## Call: principal(r = raq_data, nfactors = 4, rotate = "varimax")
## Standardized loadings (pattern matrix) based upon correlation matrix
## RC3 RC1 RC4 RC2 h2 u2 com
## Q01 0.24 0.50 0.36 0.06 0.43 0.57 2.4
## Q02 -0.01 -0.34 0.07 0.54 0.41 0.59 1.7
## Q03 -0.20 -0.57 -0.18 0.37 0.53 0.47 2.3
## Q04 0.32 0.52 0.31 0.04 0.47 0.53 2.4
## Q05 0.32 0.43 0.24 0.01 0.34 0.66 2.5
## Q06 0.80 -0.01 0.10 -0.07 0.65 0.35 1.0
## Q07 0.64 0.33 0.16 -0.08 0.55 0.45 1.7
## Q08 0.13 0.17 0.83 0.01 0.74 0.26 1.1
## Q09 -0.09 -0.20 0.12 0.65 0.48 0.52 1.3
## Q10 0.55 0.00 0.13 -0.12 0.33 0.67 1.2
## Q11 0.26 0.21 0.75 -0.14 0.69 0.31 1.5
## Q12 0.47 0.52 0.09 -0.08 0.51 0.49 2.1
## Q13 0.65 0.23 0.23 -0.10 0.54 0.46 1.6
## Q14 0.58 0.36 0.14 -0.07 0.49 0.51 1.8
## Q15 0.46 0.22 0.29 -0.19 0.38 0.62 2.6
## Q16 0.33 0.51 0.31 -0.12 0.49 0.51 2.6
## Q17 0.27 0.22 0.75 -0.04 0.68 0.32 1.5
## Q18 0.68 0.33 0.13 -0.08 0.60 0.40 1.5
## Q19 -0.15 -0.37 -0.03 0.43 0.34 0.66 2.2
## Q20 -0.04 0.68 0.07 -0.14 0.48 0.52 1.1
## Q21 0.29 0.66 0.16 -0.07 0.55 0.45 1.5
## Q22 -0.19 0.03 -0.10 0.65 0.46 0.54 1.2
## Q23 -0.02 0.17 -0.20 0.59 0.41 0.59 1.4
##
## RC3 RC1 RC4 RC2
## SS loadings 3.73 3.34 2.55 1.95
## Proportion Var 0.16 0.15 0.11 0.08
## Cumulative Var 0.16 0.31 0.42 0.50
## Proportion Explained 0.32 0.29 0.22 0.17
## Cumulative Proportion 0.32 0.61 0.83 1.00
##
## Mean item complexity = 1.8
## Test of the hypothesis that 4 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.06
## with the empirical chi square 4006.15 with prob < 0
##
## Fit based upon off diagonal values = 0.96Interpreting the factor loading matrix is a little complex, so we can make it easier by using the print.psych() function, which we can use to exclude loading below a cutoff from the display and order the variables by their loading within each factor. In the following, we will only display loadings that exceed the value 0.3.
print.psych(pc3, cut = 0.3, sort = TRUE)## Principal Components Analysis
## Call: principal(r = raq_data, nfactors = 4, rotate = "varimax")
## Standardized loadings (pattern matrix) based upon correlation matrix
## item RC3 RC1 RC4 RC2 h2 u2 com
## Q06 6 0.80 0.65 0.35 1.0
## Q18 18 0.68 0.33 0.60 0.40 1.5
## Q13 13 0.65 0.54 0.46 1.6
## Q07 7 0.64 0.33 0.55 0.45 1.7
## Q14 14 0.58 0.36 0.49 0.51 1.8
## Q10 10 0.55 0.33 0.67 1.2
## Q15 15 0.46 0.38 0.62 2.6
## Q20 20 0.68 0.48 0.52 1.1
## Q21 21 0.66 0.55 0.45 1.5
## Q03 3 -0.57 0.37 0.53 0.47 2.3
## Q12 12 0.47 0.52 0.51 0.49 2.1
## Q04 4 0.32 0.52 0.31 0.47 0.53 2.4
## Q16 16 0.33 0.51 0.31 0.49 0.51 2.6
## Q01 1 0.50 0.36 0.43 0.57 2.4
## Q05 5 0.32 0.43 0.34 0.66 2.5
## Q08 8 0.83 0.74 0.26 1.1
## Q17 17 0.75 0.68 0.32 1.5
## Q11 11 0.75 0.69 0.31 1.5
## Q09 9 0.65 0.48 0.52 1.3
## Q22 22 0.65 0.46 0.54 1.2
## Q23 23 0.59 0.41 0.59 1.4
## Q02 2 -0.34 0.54 0.41 0.59 1.7
## Q19 19 -0.37 0.43 0.34 0.66 2.2
##
## RC3 RC1 RC4 RC2
## SS loadings 3.73 3.34 2.55 1.95
## Proportion Var 0.16 0.15 0.11 0.08
## Cumulative Var 0.16 0.31 0.42 0.50
## Proportion Explained 0.32 0.29 0.22 0.17
## Cumulative Proportion 0.32 0.61 0.83 1.00
##
## Mean item complexity = 1.8
## Test of the hypothesis that 4 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.06
## with the empirical chi square 4006.15 with prob < 0
##
## Fit based upon off diagonal values = 0.96After obtaining the rotated matrix, variables with high loading are used for interpreting (=naming) the factor. Note that factor loading can be positive or negative (depends on scaling of the variable), thus take care when interpreting! Look for simple structure: each variable (hopefully) loads high on 1 factor and low on other factors.
As an example, we could name our factors as follows:
- Factor 1: fear of computers
- Factor 2: fear of statistics
- Factor 3: fear of maths
- Factor 4: Peer evaluation
The previous type of rotation (i.e., “varimax”) assumed that the the factors are independent. Oblique rotation is another type of rotation that can handle correlation between the factors. The command for an oblique rotation is very similar to that for an orthogonal rotation – we just change the rotate option from “varimax” to “oblimin.”
pc4 <- principal(raq_data, nfactors = 4, rotate = "oblimin",
scores = TRUE)
print.psych(pc4, cut = 0.3, sort = TRUE)## Principal Components Analysis
## Call: principal(r = raq_data, nfactors = 4, rotate = "oblimin", scores = TRUE)
## Standardized loadings (pattern matrix) based upon correlation matrix
## item TC1 TC4 TC3 TC2 h2 u2 com
## Q06 6 0.87 0.65 0.35 1.1
## Q18 18 0.70 0.60 0.40 1.1
## Q07 7 0.64 0.55 0.45 1.2
## Q13 13 0.64 0.54 0.46 1.1
## Q10 10 0.57 0.33 0.67 1.2
## Q14 14 0.57 0.49 0.51 1.3
## Q12 12 0.45 0.43 0.51 0.49 2.0
## Q15 15 0.40 0.38 0.62 1.9
## Q08 8 0.90 0.74 0.26 1.0
## Q11 11 0.78 0.69 0.31 1.0
## Q17 17 0.78 0.68 0.32 1.0
## Q20 20 0.71 0.48 0.52 1.1
## Q21 21 0.60 0.55 0.45 1.3
## Q03 3 -0.51 0.53 0.47 1.8
## Q04 4 0.41 0.47 0.53 2.6
## Q16 16 0.41 0.49 0.51 2.4
## Q01 1 0.33 0.40 0.43 0.57 2.4
## Q05 5 0.34 0.34 0.66 2.7
## Q22 22 0.65 0.46 0.54 1.2
## Q09 9 0.63 0.48 0.52 1.4
## Q23 23 0.61 0.41 0.59 1.6
## Q02 2 -0.36 0.51 0.41 0.59 1.9
## Q19 19 -0.35 0.38 0.34 0.66 2.1
##
## TC1 TC4 TC3 TC2
## SS loadings 3.90 2.88 2.94 1.85
## Proportion Var 0.17 0.13 0.13 0.08
## Cumulative Var 0.17 0.29 0.42 0.50
## Proportion Explained 0.34 0.25 0.25 0.16
## Cumulative Proportion 0.34 0.59 0.84 1.00
##
## With component correlations of
## TC1 TC4 TC3 TC2
## TC1 1.00 0.44 0.36 -0.18
## TC4 0.44 1.00 0.31 -0.10
## TC3 0.36 0.31 1.00 -0.17
## TC2 -0.18 -0.10 -0.17 1.00
##
## Mean item complexity = 1.6
## Test of the hypothesis that 4 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.06
## with the empirical chi square 4006.15 with prob < 0
##
## Fit based upon off diagonal values = 0.96The component correlations indicate that the factors might indeed be correlated, so oblique rotation might actually be more appropriate in this case.
8.2.4 Creating new variables
Once we have decided on the final model, we can calculate the new variables as the weighted sum of the variables that form a factor. This means, we estimate a person’s score on a factor based on their scores on the items that constitute the measurement scales. These scores are also referred to as the factor scores. Because we have used the scores = TRUE argument in the previous command, the factor scores have already been created for us. By default, R uses the regression method to compute the factor scores, which controls for differences in the units of measurement. You can access the residuals as follows:
head(pc4$scores)## TC1 TC4 TC3 TC2
## [1,] 0.37296709 1.8808424 0.95979596 0.3910711
## [2,] 0.63334164 0.2374679 0.29090777 -0.3504080
## [3,] 0.39712768 -0.1056263 -0.09333769 0.9249353
## [4,] -0.78741595 0.2956628 -0.77703307 0.2605666
## [5,] 0.04425942 0.6815179 0.59786611 -0.6912687
## [6,] -1.70018648 0.2091685 0.02784164 0.6653081We can also use the cbind() function to add the computed factor scores to the existing data set:
raq_data <- cbind(raq_data, pc4$scores)This way, it is easier to use the new variables in subsequent analysis (e.g., t-tests, regression, ANOVA, cluster analysis).
8.3 Reliability analysis
When you are using multi-item scales to measure a latent construct (e.g., the output from the PCA above), it is useful to check the reliability of your scale. Reliability means that our items should consistently reflect the construct that they are intended to measure. In other words, individual items should produce results consistent with the overall scale. This means that for a scale to be reliable, the score of a person on one half of the items should be similar to the score derived based on the other half of the items (split-half reliability). The problem is that there are several ways in which data can be split. A measure that reflects this underlying intuition is Cronbach’s alpha, which is approximately equal to the average of all possible split-half reliabilities. It is computed as follows:
\[\begin{equation} \alpha=\frac{N^2\overline{Cov}}{\sum{s^2_{item}}+\sum{Cov_{item}}} \tag{8.8} \end{equation}\]
The share of the items common variance (inter-correlation) in the total variance is supposed to be as high as possible across all items. The thresholds are as follows:
- >0.7 reasonable for practical application/exploratory research
- >0.8 necessary for fundamental research
- >0.9 desirable for applied research
To see if the subscales that were derived from the previous PCA exhibit a sufficient degree of reliability, we first create subsets of our data set that contain the respective items for each of the factors (we use the results from the oblimin rotation here):
computer_fear <- raq_data[, c(6, 7, 10, 13, 14, 15,
18)]
statistics_fear <- raq_data[, c(1, 3, 4, 5, 12, 16,
20, 21)]
math_fear <- raq_data[, c(8, 11, 17)]
peer_evaluation <- raq_data[, c(2, 9, 19, 22, 23)]Now we can use the alpha() function from the psych package to test the reliability. Note that the keys argument may be used to indicate reverse coded items. In the example below, the second item of the “statistics_fear” factor is reverse coded as indicated by the -1, meaning that it is phrased in a “positive” way, while the remaining items belonging to this factor are phrased in a “negative” way. This is often done to check if respondents are giving consistent answers.
psych::alpha(computer_fear)##
## Reliability analysis
## Call: psych::alpha(x = computer_fear)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.82 0.82 0.81 0.4 4.6 0.0052 3.4 0.71 0.39
##
## lower alpha upper 95% confidence boundaries
## 0.81 0.82 0.83
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## Q06 0.79 0.79 0.77 0.38 3.7 0.0063 0.0081 0.38
## Q07 0.79 0.79 0.77 0.38 3.7 0.0063 0.0079 0.36
## Q10 0.82 0.82 0.80 0.44 4.7 0.0053 0.0043 0.44
## Q13 0.79 0.79 0.77 0.39 3.8 0.0062 0.0081 0.38
## Q14 0.80 0.80 0.77 0.39 3.9 0.0060 0.0085 0.36
## Q15 0.81 0.81 0.79 0.41 4.2 0.0056 0.0095 0.44
## Q18 0.79 0.78 0.76 0.38 3.6 0.0064 0.0058 0.38
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## Q06 2571 0.75 0.74 0.68 0.62 3.8 1.12
## Q07 2571 0.75 0.73 0.68 0.62 3.1 1.10
## Q10 2571 0.54 0.57 0.44 0.40 3.7 0.88
## Q13 2571 0.72 0.73 0.67 0.61 3.6 0.95
## Q14 2571 0.70 0.70 0.64 0.58 3.1 1.00
## Q15 2571 0.64 0.64 0.54 0.49 3.2 1.01
## Q18 2571 0.76 0.76 0.72 0.65 3.4 1.05
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## Q06 0.06 0.10 0.13 0.44 0.27 0
## Q07 0.09 0.24 0.26 0.34 0.07 0
## Q10 0.02 0.10 0.18 0.57 0.14 0
## Q13 0.03 0.12 0.25 0.48 0.12 0
## Q14 0.07 0.18 0.38 0.31 0.06 0
## Q15 0.06 0.18 0.30 0.39 0.07 0
## Q18 0.06 0.12 0.31 0.37 0.14 0psych::alpha(statistics_fear, keys = c(1, -1, 1, 1,
1, 1, 1, 1))##
## Reliability analysis
## Call: psych::alpha(x = statistics_fear, keys = c(1, -1, 1, 1, 1, 1,
## 1, 1))
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.82 0.82 0.81 0.37 4.7 0.0053 3 0.64 0.4
##
## lower alpha upper 95% confidence boundaries
## 0.81 0.82 0.83
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## Q01 0.80 0.80 0.79 0.37 4.1 0.0060 0.0052 0.40
## Q03- 0.80 0.80 0.79 0.37 4.1 0.0061 0.0070 0.40
## Q04 0.80 0.80 0.78 0.36 4.0 0.0062 0.0061 0.35
## Q05 0.81 0.81 0.80 0.38 4.2 0.0058 0.0058 0.41
## Q12 0.80 0.80 0.79 0.36 4.0 0.0061 0.0067 0.39
## Q16 0.79 0.80 0.78 0.36 3.9 0.0062 0.0057 0.35
## Q20 0.82 0.82 0.80 0.40 4.6 0.0055 0.0022 0.41
## Q21 0.79 0.80 0.78 0.36 3.9 0.0063 0.0063 0.38
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## Q01 2571 0.65 0.67 0.60 0.54 3.6 0.83
## Q03- 2571 0.69 0.67 0.60 0.55 2.6 1.08
## Q04 2571 0.69 0.70 0.64 0.58 3.2 0.95
## Q05 2571 0.63 0.63 0.55 0.49 3.3 0.96
## Q12 2571 0.69 0.69 0.63 0.57 2.8 0.92
## Q16 2571 0.71 0.71 0.67 0.60 3.1 0.92
## Q20 2571 0.58 0.56 0.47 0.42 2.4 1.04
## Q21 2571 0.72 0.71 0.67 0.61 2.8 0.98
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## Q01 0.02 0.07 0.29 0.52 0.11 0
## Q03 0.03 0.17 0.34 0.26 0.19 0
## Q04 0.05 0.17 0.36 0.37 0.05 0
## Q05 0.04 0.18 0.29 0.43 0.06 0
## Q12 0.09 0.23 0.46 0.20 0.02 0
## Q16 0.06 0.16 0.42 0.33 0.04 0
## Q20 0.22 0.37 0.25 0.15 0.02 0
## Q21 0.09 0.29 0.34 0.26 0.02 0psych::alpha(math_fear)##
## Reliability analysis
## Call: psych::alpha(x = math_fear)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.82 0.82 0.75 0.6 4.5 0.0062 3.7 0.75 0.59
##
## lower alpha upper 95% confidence boundaries
## 0.81 0.82 0.83
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## Q08 0.74 0.74 0.59 0.59 2.8 0.010 NA 0.59
## Q11 0.74 0.74 0.59 0.59 2.9 0.010 NA 0.59
## Q17 0.77 0.77 0.63 0.63 3.4 0.009 NA 0.63
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## Q08 2571 0.86 0.86 0.76 0.68 3.8 0.87
## Q11 2571 0.86 0.86 0.75 0.68 3.7 0.88
## Q17 2571 0.85 0.85 0.72 0.65 3.5 0.88
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## Q08 0.03 0.06 0.19 0.58 0.15 0
## Q11 0.02 0.06 0.22 0.53 0.16 0
## Q17 0.03 0.10 0.27 0.52 0.08 0psych::alpha(peer_evaluation)##
## Reliability analysis
## Call: psych::alpha(x = peer_evaluation)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.57 0.57 0.53 0.21 1.3 0.013 3.4 0.65 0.23
##
## lower alpha upper 95% confidence boundaries
## 0.54 0.57 0.6
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## Q02 0.52 0.52 0.45 0.21 1.07 0.015 0.0028 0.23
## Q09 0.48 0.48 0.41 0.19 0.92 0.017 0.0036 0.22
## Q19 0.52 0.53 0.46 0.22 1.11 0.015 0.0055 0.23
## Q22 0.49 0.49 0.43 0.19 0.96 0.016 0.0065 0.19
## Q23 0.56 0.57 0.50 0.25 1.32 0.014 0.0014 0.24
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## Q02 2571 0.56 0.61 0.45 0.34 4.4 0.85
## Q09 2571 0.70 0.66 0.53 0.39 3.2 1.26
## Q19 2571 0.61 0.60 0.42 0.32 3.7 1.10
## Q22 2571 0.64 0.64 0.50 0.38 3.1 1.04
## Q23 2571 0.53 0.53 0.31 0.24 2.6 1.04
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## Q02 0.01 0.04 0.08 0.31 0.56 0
## Q09 0.08 0.28 0.23 0.20 0.20 0
## Q19 0.02 0.15 0.22 0.33 0.29 0
## Q22 0.05 0.26 0.34 0.26 0.10 0
## Q23 0.12 0.42 0.27 0.12 0.06 0The above output would lead us to conclude that the fear of computers, fear of statistics and fear of maths subscales of the RAQ all had sufficiently high levels of reliability (i.e., Cronbach’s alpha > 0.70). However, the fear of negative peer evaluation subscale had relatively low reliability (Cronbach’s alpha = 0.57). As the output under “Reliability if an item is dropped” suggests, the alpha score would also not increase if an item was dropped from the scale.
As another example, consider the multi-item scale from the statistical ability questionnaire.
test_data <- read.table("https://raw.githubusercontent.com/IMSMWU/Teaching/master/MRDA2017/survey2017.dat",
sep = "\t", header = TRUE)
head(test_data)The four variables “multi_1” - “multi_4” represent the multi-item scales. We can test the reliability of the scale using the alpha() function (item 4 was reverse coded, hence the “-1” in the keys vector):
psych::alpha(test_data[, c("multi_1", "multi_2", "multi_3",
"multi_4")], keys = c(1, 1, 1, -1))##
## Reliability analysis
## Call: psych::alpha(x = test_data[, c("multi_1", "multi_2", "multi_3",
## "multi_4")], keys = c(1, 1, 1, -1))
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.9 0.9 0.88 0.68 8.7 0.024 2.7 0.92 0.65
##
## lower alpha upper 95% confidence boundaries
## 0.85 0.9 0.94
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## multi_1 0.85 0.86 0.81 0.66 5.9 0.035 0.0101 0.61
## multi_2 0.83 0.83 0.77 0.63 5.0 0.039 0.0028 0.61
## multi_3 0.86 0.86 0.83 0.68 6.3 0.034 0.0195 0.61
## multi_4- 0.91 0.91 0.88 0.77 10.0 0.022 0.0058 0.78
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## multi_1 55 0.89 0.89 0.86 0.80 2.7 1.0
## multi_2 55 0.92 0.92 0.92 0.85 2.6 1.0
## multi_3 55 0.88 0.88 0.83 0.78 2.5 1.1
## multi_4- 55 0.81 0.80 0.68 0.65 2.8 1.1
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## multi_1 0.11 0.36 0.25 0.25 0.02 0
## multi_2 0.11 0.42 0.25 0.18 0.04 0
## multi_3 0.18 0.38 0.22 0.20 0.02 0
## multi_4 0.04 0.31 0.16 0.40 0.09 0Since the scale exhibits a sufficient degree of reliability, we can compute the new variable as the average score on these items. However, before doing this, we need to recode the reverse coded variable in the appropriate way. It is easy to recode the reverse coded item to be in line with the remaining items on the dimension using the recode() function from the car package.
library(car)
test_data$multi_4_rec = recode(test_data$multi_4, "1=5; 2=4; 3=3; 4=2; 5=1")Now we can compute the new variable as the average score of the four items:
library(car)
test_data$new_variable = (test_data$multi_1 + test_data$multi_2 +
test_data$multi_3 + test_data$multi_4_rec)/4
head(test_data)Learning check
(LC8.1) The goals of factor analysis are…
- …to identify underlying dimensions that explain correlations among variables.
- …to identify multiplicative effects in a linear regression.
- …to identify a smaller set of uncorrelated variables.
- …to identify interaction terms in a linear regression.
- None of the above
(LC8.2) What are typical hypotheses in exploratory factor analysis (EFA) concerning how many factors will emerge?
- A reduction greater than 50% of the input variables
- Between a third and a fourth of the input variables
- A reduction smaller than 50% of the input variables
- None of the above
(LC8.3) What assumptions have to be fulfilled for using factor analysis?
- Variables must be in interval or ratio scale
- Existence of some underlying factor structure
- The correlation matrix must have sufficient number of correlations
- Variables must be measured using ordinal scales
- None of the above
(LC8.4) What is the correct interpretation of the b-values in the following mathematical representation concerning exploratory factor analysis (EFA)? \(Factor_i=b_1*Variable_1 + b_2*Variable_2+…+b_nVariable_n\)
- Regression coefficients
- Correlations between the variables
- Weights of a variable on a factor
- Factor loadings
- None of the above
(LC8.5) What is the null hypothesis of the Bartlett’s test of sphericity?
- All variables are correlated in the population
- The correlation matrix is singular
- All variables are uncorrelated in the population
- The correlation matrix is an identity matrix
- None of the above
(LC8.6) Before conducting PCA, how can you test the sampling adequacy of your data (i.e., how suited your data is for Factor Analysis)?
- Kaiser-Meyer-Olkin (KMO) test with scores <0.5
- Kaiser-Meyer-Olkin (KMO) test with scores >0.5
- By inspecting the scree plot
- Cronbach’s alpha test with scores >0.7
- None of the above
(LC8.7) What is communality?
- Proportion of common variance in a variable
- Variance that is unique to a particular variable
- Proportion of unique variance in a variable
- Covariance between two factors
- None of the above
(LC8.8) Orthogonal factor rotation assumes:
- Inter-correlated factors
- Uncorrelated factors
- Outer-correlated factors
- None of the above
(LC8.9) Imagine you want to conduct a PCA on 10 variables without factor rotation and in a first step, you wish to find out how many components you should extract. How would the corresponding R Code look?
-
principal(data, nfactors = 10, rotate = "none") -
principal(data, nfactors = “varimax”, rotate = 10) -
principal(data, nfactors = 10, rotate = "oblimin") -
principal(data, nfactors = 10, rotate = "varimax") - None of the above
(LC8.10) Which of the following statements concerning reliability and validity are TRUE?
- Validity (i.e. “consistency”) requires the absence of random errors
- Reliability (i.e. “truthfulness”) requires the absence of measurement errors
- Validity describes the extent to which a scale produces consistent results in repeated measurements
- None of the above
References
- Field, A., Miles J., & Field, Z. (2012): Discovering Statistics Using R. Sage Publications, chapter 17
- Malhotra, N. K.(2010). Marketing Research: An Applied Orientation (6th. ed.). Prentice Hall. chapter 19